Lots of stuff, apparently unrelated, but it all came together recently, so here it is. Probably the whole thing is useless, but along the way I found many interesting things.
The network topology used for this experiment is as follows:
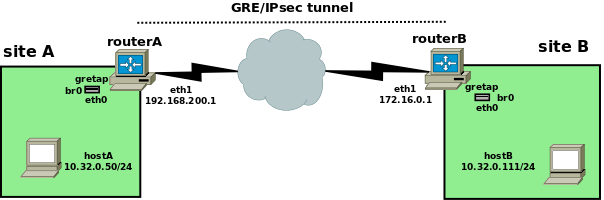
The initial task was trying to find a way to bridge site A and site B using IPsec (for starters, something that's not terribly useful; and yes, I know that there are other ways, but that's not the point here), I came across the (utterly undocumented) gretap tunnel of iproute2, which is, well, a GRE interface that can encapsulate ethernet frames (rather than IP packets, which is the more usual use case for GRE).
A gretap interface is created thus:
routerA# ip link add gretap type gretap local 192.168.200.1 remote 172.16.0.1 dev eth1
routerA# ip link show gretap
6: gretap@eth1: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 62:24:67:45:44:ad brd ff:ff:ff:ff:ff:ff
The idea is: add the gretap interface to a bridge at both ends of the tunnel, and voila, site A and site B are bridged. Then, use IPsec to encrypt the GRE traffic between the sites: mission accomplished. Right? No. Turns out it isn't so easy. Let's go step by step.
The MTU problem
As shown above, when the gretap interface is created, it has a default MTU of 1462, which is correct: 1500 (underlying physical interface) - 20 (outer IP header added by GRE) - 4 (GRE header) - 14 (ethernet header of the encapsulated frame) = 1462.
However, the rest of machines in the LAN have an MTU of 1500, of course.
For a normal GRE interface (encapsulating pure IP) a lower tunnel MTU is a bit of an annoyance, but nothing critical: when a packet too big is received, an ICMP error (type 3, code 4 for IPv4) is sent back to the originator of the packet, which will then hopefully take the necessary actions (lower its MTU, retransmit but this time allowing fragmentation, whatever).
However here with our gretap interface we're bridging, which means that there's no "previous hop" where to send the ICMP error.
Furthermore, since the gretap interface is added to a bridge, the bridge MTU is lowered in turn. Since ethernet networks work on the assumption that all the participating interfaces have the same MTU, if a bridge with an MTU of 1462 (maximum frame size 1476) receives a full-sized frame (up to 1514 bytes), it just silently drops it. Not nice, although there's nothing else it can do.
To check, let's add the gretap interface to a bridge on routerA:
routerA# ip link add br0 type bridge routerA# ip link set eth0 down routerA# ip addr del 10.32.x.x/24 dev eth0 # remove whatever IP address it had routerA# ip link set eth0 master br0 routerA# ip link set eth0 up routerA# ip link set br0 up routerA# ip addr add 10.0.0.254/24 dev br0 routerA# ip link set gretap up routerA# ip link set gretap master br0
and the same on routerB:
routerB# ip link add br0 type bridge routerB# ip link set eth0 down routerB# ip addr del 10.32.x.x/24 dev eth0 # remove whatever IP address it had routerB# ip link set eth0 master br0 routerB# ip link set eth0 up routerB# ip link set br0 up routerB# ip addr add 10.0.0.253/24 dev br0 routerB# ip link set gretap up routerB# ip link set gretap master br0
(we assign 10.32.0.253 to br0 on routerB to avoid conflicts, since the networks are bridged; these addresses are not used for these examples, anyway).
Now, from host A, we produce a maximum-sized frame:
hostA# ping -s 1472 10.32.0.111 PING 10.32.0.111 (10.32.0.111) 1472(1500) bytes of data. ^C --- 10.32.0.111 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2015ms
If we capture the traffic, we see that the small ARP request/reply frames pass through the tunnel, but the frames containing the actual ICMP echo request packets are silently dropped by br0 at routerA (which at this point still has an MTU of 1462).
Seems like the obvious thing to do is to raise the MTU of the gretap interface to 1500, so the bridge can have an MTU of 1500 again:
routerA# ip link show br0
4: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1462 qdisc noqueue state UP mode DEFAULT
link/ether 00:16:3e:c3:8c:ef brd ff:ff:ff:ff:ff:ff
routerA# ip link set gretap mtu 1500
routerA# ip link show br0
4: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT
link/ether 00:16:3e:c3:8c:ef brd ff:ff:ff:ff:ff:ff
and the same thing at routerB. Are we done now? Of course no, because while now the bridge does accept full-sized frames, there is a problem when a big frame has to be sent out the gretap "bridge port": after encapsulation, the size of the resulting IP packet can be up to 1514 + 4 + 20 = 1538 bytes. It may or may not be possible to fragment it, and here comes the next interesting point.
IP fragmentation
Now it turns out that, by default, GRE interfaces do Path MTU Discovery (PMTUD for short), which means the packets they produce have the DF (Don't Fragment) flag bit set. As mentioned above, this behavior is useful when encapsulating IP, so the previous hop can be notified of the tunnel bottleneck if needed. But again, here we're encapsulating ethernet and bridging, so there's noone to notify: if the oversized packet cannot be fragmented (and by default it can't, since PMTUD is performed), it's just dropped.
What we want, ideally, is that the encapsulated packets resulting from gretap encapsulation be fragmentable, that is, have the DF bit set to 0. It should be possible to do it, right?
Reading through the scarce iproute2 documentation, we learn that tunnel interfaces can be given a special option nopmtudisc at creation time, whose function, according to the manual, is to "disable Path MTU Discovery on this tunnel." Sounds just like the feature we want, so let's set the flag when creating the interface:
routerA# ip link del gretap routerA# ip link add gretap type gretap local 192.168.200.1 remote 172.16.0.1 dev eth1 nopmtudisc routerA# ip link set gretap mtu 1500 routerA# ip link set gretap up routerA# ip link set gretap master br0
(same at routerB). However, if we now retry the oversized ping (-s 1472), it still doesn't work. How is that? A sample traffic capture shows that IP packets leaving hostA have the DF bit set, and apparently this bit gets copied to the outer IP header added by GRE (despite the nopmtudisc flag), which thus results in an unfragmentable packet which is silently dropped. If we explicitly disable DF on the IP packets produced by ping, it finally works:
ping -Mdont -s 1472 10.32.0.111 PING 10.32.0.111 (10.32.0.111) 1472(1500) bytes of data. 1480 bytes from 10.32.0.111: icmp_req=1 ttl=64 time=1.26 ms 1480 bytes from 10.32.0.111: icmp_req=2 ttl=64 time=0.932 ms 1480 bytes from 10.32.0.111: icmp_req=3 ttl=64 time=1.01 ms ^C --- 10.32.0.111 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 0.932/1.071/1.264/0.143 ms
and capturing outgoing traffic at routerA and routerB show fragmented GRE/IP packets (yes, fragments are bad, but probably better than nothing at all).
However, this is no solution, since we artificially modified the behavior of the application on the client, which is not doable for all the LAN hosts.
More bad news: Linux (and probably most operating systems) performs PMTUD by default, meaning that each and every IP packet produced by applications has the DF bit set (unless overridden by the application, which is not usual). There is a /proc entry that can disable this behavior on a global basis (/proc/sys/net/ipv4/ip_no_pmtu_disc
Here are some ugly drawings showing how the gretap encapsulation works. First, there's the original ethernet frame, which can be up to 1514 bytes (1500 IP + 14 ethernet header):

When this frame is encapsulated, we get this:

Clearing DF: NFQUEUE
One may imagine that it should be possible to perform this apparently simple using standard tools; after all, it's "normal" packet mangling, which iptables can perform. Again, it turns out it's not so easy. There seems to be no native iptables way to do this (while it can touch other parts of the IP header, like TTL or TOS).
However, what iptables does have is a generic mechanism to pass packets to userspace: to use it, we create iptables rules that match the packets we want and apply the NFQUEUE (formerly QUEUE) target to them. Then, a user-space program can register to receive and process these packets, and decide their fate (or "verdict" in nfqueue speak): send them back to iptables (after optionally modifying them), or discard them. The mechanism used for this communication is called nfnetlink. The library is in C, but Perl and Python bindings exist.
Before writing the actual code, however, we have to create the iptables rule that matches the tunneled packets. Thinking about it a bit, it's not obvious which tables and chains it would traverse on the router. Would it traverse the INPUT chain? It's not destined to the local machine (or is it?). What about the OUTPUT chain? It's not locally generated (or is it?). Fortunately, in this case an easy way exists to clear all doubts, since iptables allows tracing and the complete set of tables and chains that are traversed can be easily seen and logged.
1 TRACE: raw:PREROUTING:policy:2 IN=br0 OUT= PHYSIN=eth0 MAC=00:16:3e:52:ba:6c:00:16:3e:93:08:ca:08:00 SRC=10.32.0.50 DST=10.32.0.111 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=819 SEQ=1 2 TRACE: filter:FORWARD:policy:1 IN=br0 OUT=br0 PHYSIN=eth0 PHYSOUT=gretap MAC=00:16:3e:52:ba:6c:00:16:3e:93:08:ca:08:00 SRC=10.32.0.50 DST=10.32.0.111 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=819 SEQ=1 3 TRACE: raw:OUTPUT:rule:1 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=122 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=47 4 TRACE: raw:OUTPUT:policy:2 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=122 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=47 5 TRACE: filter:OUTPUT:policy:2 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=122 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=47 6 TRACE: raw:PREROUTING:policy:2 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=122 TOS=0x00 PREC=0x00 TTL=63 ID=40301 PROTO=47 7 TRACE: filter:INPUT:policy:1 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=122 TOS=0x00 PREC=0x00 TTL=63 ID=40301 PROTO=47 8 TRACE: raw:PREROUTING:rule:1 IN=br0 OUT= PHYSIN=gretap MAC=00:16:3e:93:08:ca:00:16:3e:52:ba:6c:08:00 SRC=10.32.0.111 DST=10.32.0.50 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=18065 PROTO=ICMP TYPE=0 CODE=0 ID=819 SEQ=1 9 TRACE: raw:PREROUTING:policy:2 IN=br0 OUT= PHYSIN=gretap MAC=00:16:3e:93:08:ca:00:16:3e:52:ba:6c:08:00 SRC=10.32.0.111 DST=10.32.0.50 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=18065 PROTO=ICMP TYPE=0 CODE=0 ID=819 SEQ=1 10 TRACE: filter:FORWARD:policy:1 IN=br0 OUT=br0 PHYSIN=gretap PHYSOUT=eth0 MAC=00:16:3e:93:08:ca:00:16:3e:52:ba:6c:08:00 SRC=10.32.0.111 DST=10.32.0.50 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=18065 PROTO=ICMP TYPE=0 CODE=0 ID=819 SEQ=1
Lines 1 to 5 show the outgoing packet, and lines 6 to 10 the return packet containing the ICMP echo reply.
Since a bridge is involved, the actual result depends on whether the /proc entry /proc/sys/net/bridge/bridge-nf-call-iptables
So where do we tap into the flow to get our packets? Obviously we want to see the GRE packets, not the raw ethernet traffic (so whether iptables is called for bridge traffic or not is not important here), and we're only interested in traffic from the local LAN to the tunnel (lines 3 to 5 in the above trace). So a good place could be the OUTPUT chain, either in the raw or the filter table. Let's choose the filter table which is more common:
routerA# iptables -A OUTPUT -s 192.168.200.1 -d 172.16.0.1 -p gre -j NFQUEUE --queue-bypass routerB# iptables -A OUTPUT -s 172.16.0.1 -d 192.168.200.1 -p gre -j NFQUEUE --queue-bypass
This sends all matching traffic to the NFQUEUE queue number 0 (the default), and moves on the next rule or policy if there's no user application listening on that queue (the --queue-bypass part), so at least small packets can pass by default.
Clearing DF, finally
Now all that's left is writing the user code that receives packets from queue 0, clears the DF bit, and sends them back to iptables. Fortunately, the library provides some sample C code that can be adapted for our purposes. So without further ado, let's fire up an editor and write this code:
/***************************************************************************************
* clear_df.c: clear, uh, DF bit from IPv4 packets. Heavily borrowed from *
* http://netfilter.org/projects/libnetfilter_queue/doxygen/nfqnl__test_8c_source.html *
***************************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <netinet/in.h>
#include <linux/types.h>
#include <linux/netfilter.h> /* for NF_ACCEPT */
#include <arpa/inet.h>
#include <time.h>
#include <libnetfilter_queue/libnetfilter_queue.h>
/* Standard IPv4 header checksum calculation, as per RFC 791 */
u_int16_t ipv4_header_checksum(char *hdr, size_t hdrlen) {
unsigned long sum = 0;
const u_int16_t *bbp;
int count = 0;
bbp = (u_int16_t *)hdr;
while (hdrlen > 1) {
/* the checksum field itself should be considered to be 0 (ie, excluded) when calculating the checksum */
if (count != 10) {
sum += *bbp;
}
bbp++; hdrlen -= 2; count += 2;
}
/* in case hdrlen was an odd number, there will be one byte left to sum */
if (hdrlen > 0) {
sum += *(unsigned char *)bbp;
}
while (sum >> 16) {
sum = (sum & 0xffff) + (sum >> 16);
}
return (~sum);
}
/* callback function; this is called for every matched packet. */
static int cb(struct nfq_q_handle *qh, struct nfgenmsg *nfmsg, struct nfq_data *nfa, void *data) {
u_int32_t queue_id;
struct nfqnl_msg_packet_hdr *ph;
int pkt_len;
char *buf;
size_t hdr_len;
/* determine the id of the packet in the queue */
ph = nfq_get_msg_packet_hdr(nfa);
if (ph) {
queue_id = ntohl(ph->packet_id);
} else {
return -1;
}
/* try to get at the actual packet */
pkt_len = nfq_get_payload(nfa, &buf);
if (pkt_len >= 0) {
hdr_len = ((buf[0] & 0x0f) * 4);
/* clear DF bit */
buf[6] &= 0xbf;
/* set new packet ID */
*((u_int16_t *)(buf + 4)) = htons((rand() % 65535) + 1);
/* recalculate checksum */
*((u_int16_t *)(buf + 10)) = ipv4_header_checksum(buf, hdr_len);
}
/* "accept" the mangled packet */
return nfq_set_verdict(qh, queue_id, NF_ACCEPT, pkt_len, buf);
}
int main(int argc, char **argv) {
struct nfq_handle *h;
struct nfq_q_handle *qh;
int fd;
int rv;
char buf[4096] __attribute__ ((aligned));
/* printf("opening library handle\n"); */
h = nfq_open();
if (!h) {
fprintf(stderr, "error during nfq_open()\n");
exit(1);
}
/* printf("unbinding existing nf_queue handler for AF_INET (if any)\n"); */
if (nfq_unbind_pf(h, AF_INET) < 0) {
fprintf(stderr, "error during nfq_unbind_pf()\n");
exit(1);
}
/* printf("binding nfnetlink_queue as nf_queue handler for AF_INET\n"); */
if (nfq_bind_pf(h, AF_INET) < 0) {
fprintf(stderr, "error during nfq_bind_pf()\n");
exit(1);
}
/* printf("binding this socket to queue '0'\n"); */
qh = nfq_create_queue(h, 0, &cb, NULL);
if (!qh) {
fprintf(stderr, "error during nfq_create_queue()\n");
exit(1);
}
/* printf("setting copy_packet mode\n"); */
if (nfq_set_mode(qh, NFQNL_COPY_PACKET, 0xffff) < 0) {
fprintf(stderr, "can't set packet_copy mode\n");
exit(1);
}
fd = nfq_fd(h);
/* initialize random number generator */
srand(time(NULL));
while ((rv = recv(fd, buf, sizeof(buf), 0)) && rv >= 0) {
nfq_handle_packet(h, buf, rv);
}
/* printf("unbinding from queue 0\n"); */
nfq_destroy_queue(qh);
/* printf("closing library handle\n"); */
nfq_close(h);
exit(0);
}
It's useful to refer to this illustration of the IPv4 header to better follow the explanation.
The main thing worth noting of the above code is that, if we clear DF, we also have to fill in the "identification" (id) field (bytes 4 and 5 of the header) of the IPv4 header. This field is generally set to 0 when DF is set, since in that case of course the packet will never be fragmented. However, we're actually allowing fragmentation for a packet for which it was possibly not intended, so we fill the id field with a random 16-bit integer between 1 and 65535; this value is used by whoever has to reassemble the packet, to tell which fragments are part of the same original packet. If we left the field to 0, then all fragments (if any) would have the same ID and the receiver would have a hard time reassembling the original packet, especially if the fragments arrive out of order.
And of course, since we're changing the header, the checksum (bytes 10 and 11 of the header) has to be recalculated.
An obvious optimization of the above code (not implemented here as it's just a proof of concept) would be to immeditaly accept the packet without mangling it if the DF bit is already set to 0. Another possibiility could be to not touch the packet if its length is less than the outgoing interface MTU (the output interface can be obtained using nfq_get_outdev, for example); however in this case we'd be trusting all the hops along the path to have an MTU greater or equal to ours, which may not be true; so when in doubt, we just always clear DF.
Compilation requires the appropriate header files to be present (libnfnetlink-dev and libnetfilter-queue-dev under debian). To compile the code, do:
gcc -o clear_df -lnfnetlink -lnetfilter_queue clear_df.c
So now, let's run our program and retry the damned ping (forcing DF, just to be sure):
routerA# clear_df routerB# clear_df hostA# ping -s 1472 -Mdo 10.32.0.111 PING 10.32.0.111 (10.32.0.111) 1472(1500) bytes of data. 1480 bytes from 10.32.0.111: icmp_req=1 ttl=64 time=1.48 ms 1480 bytes from 10.32.0.111: icmp_req=2 ttl=64 time=0.969 ms 1480 bytes from 10.32.0.111: icmp_req=3 ttl=64 time=1.11 ms 1480 bytes from 10.32.0.111: icmp_req=4 ttl=64 time=0.946 ms 1480 bytes from 10.32.0.111: icmp_req=5 ttl=64 time=0.944 ms ^C --- 10.32.0.111 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 0.944/1.091/1.481/0.208 ms
So it finally works, and without changing anything on host A. On the routers, capturing the traffic on the link between routerA and routerB does indeed show fragmented packets. So we can finally say that "it works".
Final piece: IPsec
Although this was the original goal, it somehow got lost along the road while we were troubleshooting things, so back on track after the detour. Now that we got this far, adding IPsec should be a piece of cake. To make it a bit more interesting (not much), routerA is going to use ipsec-tools + racoon, while routerB will use Openswan. These are probably the most common IPsec implementations under Linux.
Since the GRE packets already contain router A's and router B's public IPs in the IP header, effectively making this a host-to-host tunnel, we can use IPsec's transport mode to just encrypt and authenticate the payload (this is a case where transport mode is actually useful). Note however that IPsec transport mode inserts a new header (the ESP header) after the first IP header, so the "protocol" field of the latter will change from 47 (GRE) to 50 (ESP). Grafically, after ESP is applied (which however always happens before fragmentation) we now have this monster:

Should we modify the iptables rule that sends the packets to userspace? Let's see. The easiest way to check is, again, tracing a packet and seeing which chains it traverses, so if we do it we see (omitting the bridging parts which are not relevant here):
1 TRACE: raw:OUTPUT:policy:2 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=122 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=47 2 TRACE: filter:OUTPUT:rule:2 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=122 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=47 3 TRACE: raw:OUTPUT:rule:1 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=152 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=ESP SPI=0xdb28966a 4 TRACE: raw:OUTPUT:policy:2 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=152 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=ESP SPI=0xdb28966a 5 TRACE: filter:OUTPUT:policy:3 IN= OUT=eth1 SRC=192.168.200.1 DST=172.16.0.1 LEN=152 TOS=0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=ESP SPI=0xdb28966a 6 TRACE: raw:PREROUTING:policy:2 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=152 TOS=0x00 PREC=0x00 TTL=63 ID=21840 PROTO=ESP SPI=0x4802e17 7 TRACE: filter:INPUT:policy:1 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=152 TOS=0x00 PREC=0x00 TTL=63 ID=21840 PROTO=ESP SPI=0x4802e17 8 TRACE: raw:PREROUTING:rule:1 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=122 TOS=0x00 PREC=0x00 TTL=63 ID=21840 PROTO=47 9 TRACE: raw:PREROUTING:policy:2 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=122 TOS=0x00 PREC=0x00 TTL=63 ID=21840 PROTO=47 10 TRACE: filter:INPUT:policy:1 IN=eth1 OUT= MAC=00:16:3e:c3:8c:12:00:16:3e:11:b8:8e:08:00 SRC=172.16.0.1 DST=192.168.200.1 LEN=122 TOS=0x00 PREC=0x00 TTL=63 ID=21840 PROTO=47
So interestingly enough, we see that (despite Linux not having a real IPsec virtual interface) IPsec packets traverse the chains twice, once before encryption (with PROTO=47, lines 1-2) and again after encryption (with PROTO=ESP, that is, protocol 50, lines 3-5).
This means that we can either keep the existing iptables rules, in which case our code will receive the unencrypted packets, or change it to match protocol ESP (-p 50 or -p esp), in which case we'll see ESP packets. Note that we can do the latter because ESP does not protect the outer header; if we used AH (protocol 51), we wouldn't be able to change the ID field, which is considered immutable and thus authenticated - ie, signed - without rendering the packet invalid. So if we were using AH in transport mode, we would definitely want to match unencrypted packets (ie, -p 47 or -p gre). Though according to most people, AH is next to useless anyway.
However, since NFQUEUE has to copy packets between kernel space and user space and back, and since unencrypted packets are smaller, it's more efficient to match on protocol 47 (thus we're leaving the existing iptables rules unchanged).
For completeness, here are the sample IPsec confgurations used on routerA and routerB.
ipsec-tools.conf on routerA:
#!/usr/sbin/setkey -f ## Flush the SAD and SPD # flush; spdflush; spdadd 192.168.200.1/32 172.16.0.1/32 gre -P out ipsec esp/transport//require; spdadd 172.16.0.1/32 192.168.200.1/32 gre -P in ipsec esp/transport//require;
racoon.conf on routerA:
log notify;
path pre_shared_key "/etc/racoon/psk.txt";
path certificate "/etc/racoon/certs";
remote 172.16.0.1 {
exchange_mode main;
proposal {
encryption_algorithm 3des;
hash_algorithm md5;
authentication_method pre_shared_key;
dh_group modp1024;
}
}
sainfo address 192.168.200.1/32 gre address 172.16.0.1/32 gre {
pfs_group modp1024;
encryption_algorithm 3des;
authentication_algorithm hmac_md5;
compression_algorithm deflate;
}
ipsec.conf on routerB:
version 2.0 # conforms to second version of ipsec.conf specification # basic configuration config setup nhelpers=0 interfaces="%none" protostack=netkey klipsdebug="" plutodebug="" conn to-routerA type=transport left=172.16.0.1 leftsubnet=172.16.0.1/32 right=192.168.200.1 rightsubnet=192.168.200.1/32 authby=secret phase2alg=3des-md5;modp1024 keyexchange=ike ike=3des-md5;modp1024 auto=start leftprotoport=gre rightprotoport=gre
For authentication we'll use pre-shared keys, but the changes to use certificate-based authentication are trivial (and not directly related to the main point of the article anyway).
The main thing to note is that we explicitly specify in our policies that we want to encrypt GRE traffic only, since that's what carries the tunneled ethernet frames. Everything in the above configuration can be changed; the policy can be changed to encrypt all traffic (using "any"), or the hash and encryption algorithms can be changed. There's nothing magic or special; it's just plain IPsec configuration.

Hi, nice guide!
Is it possible to set the MSS with TCP and iptables when the network is bridged?
Thanks!
Best Regards
Probably, but I've never tried it.
I have created a gretap tunnel and vm's are using it via a macvtap bridge to route traffic to a host acting as a gateway. On the gateway host I configured a manual host route of the vm ip via the tunnel.
The strange thing is. If I ping from this vm to 8.8.8.8 it periodically looses traffic. Also incoming traffic is sometimes timing out.
But when i start a background process on the vm that pings the gateway ip. These timeouts disappear.
Do you have an idea, about what can cause this?
Sorry, I don't know.
Nevermind, all is working now :) I had forgotten the "nopmtudisc" option in one of the tunnel endpoints.
Actually I did have an MTU problem as a ping with "-s 1472" wouldn't work before I applied your "clear_df" solution. Performance is still terrible though :(
Hi
I've found your guide recently and it's been very helpful! Interestingly I didn't experience MTU problems (eg. pings worked fine right after bringing up the tunnels). However, performance seems to be terrible across the tunnel. I can ping fine and even ssh, but an "apt-get update", for example, stalls forever.
Have you seen this behavior?