As mentioned earlier, let's see how to add HA to a linux/iptables-based firewall by means of keepalived and conntrackd.
There are a few scenarios for firewall HA. Probably, the most common one is the "classic" active-backup case where, at any time, one firewall is active and manages traffic, and the other is a "hot standby" ready to take over if the active one fails. In principle, since all the tools we're going to use can communicate over multicast, it should be possible to extend the setup described here to more than two firewalls.
We're going to assume this network setup:
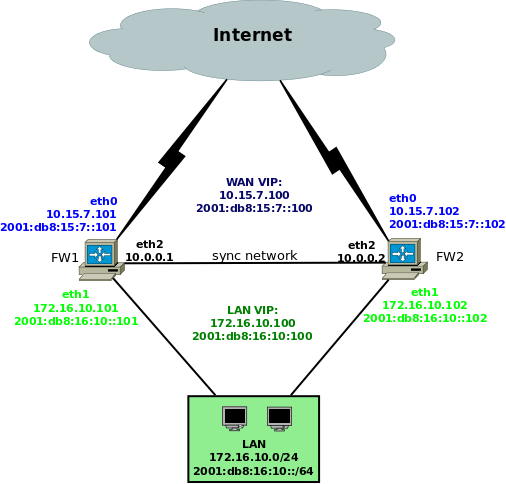
The two firewalls have a dedicated link (interface eth2 on both machines) to exchange session table synchronization messages, which is the recommended setup. If that is not possible, another interface can be used (for example, the internal LAN interface eth1). In that case, the configuration shown below should be adapted accordingly (essentially, use eth1 and 172.16.0.x instead of eth2 and 10.0.0.x, where x varies depending on the firewall). However beware that the recommendation of using a dedicated link exists for a reason: conntrackd can produce a lot of traffic. On a moderately busy firewall (about 33K connections on average), a quick test showed up to 1.6 Mbit/s of conntrackd synchronization traffic between the firewalls.
keepalived
The basic idea is that keepalived manages the failover of the (virtual) IPs using the standard VRRP protocol: at any time, the firewall that owns the virtual IPs replies to ARP requests (neighbor solicitiations for IPv6) and thus receives the traffic (this is accomplished by sending gratuitous ARPs for IPv4 and "gratuitous" neighbor advertisements for IPv6 when the firewall becomes active. Any HA product that has to move IPs uses this method).
Since the VRRP protocol performs failover of the virtual IPs, one may think that it's all that we need to get HA. For some applications, this may be true; however, in the case of stateful firewalls a crude VRRP-only failover would disrupt existing sessions. The keyword here is stateful, that is, the firewall keeps a table of active sessions with various pieces of metadata about each one. When a previously idle firewall becomes active, it suddenly starts receiving packets belonging to established sessions, which however it knows nothing about. Thus, it would kill them, or try to handle the packets locally; in all cases, sessions would be disrupted. (We will see later that this problem can still occur for short times even when using conntrackd, but can be easily solved). For small setups it may be relatively fine, but if the firewall is a busy one the failover can kill hundreds of sessions. If we're serious about HA, VRRP alone is not enough; the connection tracking table has to be kept in sync among firewalls, and this is where conntrackd comes into play.
conntrackd
Conntrackd is a complex tool. It can be used to collect traffic statistics on the firewalls, but also (and this is what we want here) to keep the stateful session table synchronized between the firewalls, so at any time they have the same information. Session information can be exchanged using a few different ways; here we're going to use the recommended method (called FTFW) which uses a reliable messaging protocol. In turn, FTFW can use multicast or unicast UDP as its transport; here we're using unicast. The sample configuration files that come with conntrackd have comments that explain how to set up multicast UDP if one wants to.
By default, there are two locations where session information is stored: the so-called internal cache is where the firewall stores its local session table (ie, sessions for which it's passing traffic; this is a (partial) copy of the kernel session table, which can be inspected with tools like conntrack - without the trailing d); then, the external cache is where the firewall stores sessions it learns from the other firewall(s). During normal operation, the firewalls continuously exchange messages to inform the peer(s) about each one's session table and its changes, so at any time each firewall knows its own and the other firewall's sessions. When using two firewalls, one firewall's internal cache should match the other's external one, and viceversa.
When a firewall becomes active following a failover, it invokes a script that commits the external cache into the kernel table, and then resyncs the internal cache using the kernel table as the origin; the result is that from that moment on the firewall can start managing sessions for which it had not seen a single packet until then, just as if it had been managing them from their beginning. This is much better than what we would get if using only pure VRRP failover.
The commit script is invoked by keepalived when it detects that the firewall is changing state. The script is called primary-backup.sh and comes with conntrackd; most distributions put it into the documentation directory (eg /usr/share/doc/conntrackd or similar). The same script is invoked upon any state change (when the firewall becomes active, backup, or fails); it knows what happened because it's passed a different argument for any possible state.
Note that it is also possible to disable the external cache (see the DisableExternalCache configuration directive). This way, all the sessions (local and learned) will always be stored directly into the kernel table/internal cache. This means that nothing needs to be done upon failover (or at most, only resyncing the internal cache with the kernel table), as the information the firewall needs to take over is already where it should be (the internal cache). So one may wonder why bother with the external cache at all; the official documentation mentions efficiency and resource usage concerns. Personally, using the external cache seems to work fairly well, so I didn't have the need to mess about and disable it.
Configuration files
Here are the configuration files used for the scenario described here. keepalived.conf:
vrrp_sync_group G1 {
group {
E1
I1
}
notify_master "/etc/conntrackd/primary-backup.sh primary"
notify_backup "/etc/conntrackd/primary-backup.sh backup"
notify_fault "/etc/conntrackd/primary-backup.sh fault"
}
vrrp_instance E1 {
interface eth0
state BACKUP
virtual_router_id 61
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass zzzz
}
virtual_ipaddress {
10.15.7.100/24 dev eth0
2001:db8:15:7::100/64 dev eth0
}
nopreempt
garp_master_delay 1
}
vrrp_instance I1 {
interface eth1
state BACKUP
virtual_router_id 62
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass zzzz
}
virtual_ipaddress {
172.16.10.100/24 dev eth1
2001:db8:16:10::100/64 dev eth1
}
nopreempt
garp_master_delay 1
}
The above is from fw1; on fw2 it's the same but the priority of each instance is 50 instead of 100.
conntrackd.conf (comments removed):
Sync {
Mode FTFW {
DisableExternalCache Off
CommitTimeout 1800
PurgeTimeout 5
}
UDP {
IPv4_address 10.0.0.1
IPv4_Destination_Address 10.0.0.2
Port 3780
Interface eth2
SndSocketBuffer 1249280
RcvSocketBuffer 1249280
Checksum on
}
}
General {
Nice -20
HashSize 32768
HashLimit 131072
LogFile on
Syslog on
LockFile /var/lock/conntrack.lock
UNIX {
Path /var/run/conntrackd.ctl
Backlog 20
}
NetlinkBufferSize 2097152
NetlinkBufferSizeMaxGrowth 8388608
Filter From Userspace {
Protocol Accept {
TCP
UDP
ICMP # This requires a Linux kernel >= 2.6.31
}
Address Ignore {
IPv4_address 127.0.0.1 # loopback
IPv4_address 10.0.0.1
IPv4_address 10.0.0.2
IPv4_address 172.16.10.100
IPv4_address 172.16.10.101
IPv4_address 172.16.10.102
IPv4_address 10.15.7.100
IPv4_address 10.15.7.101
IPv4_address 10.15.7.102
IPv6_address 2001:db8:15:7::100
IPv6_address 2001:db8:15:7::101
IPv6_address 2001:db8:15:7::102
IPv6_address 2001:db8:16:10::100
IPv6_address 2001:db8:16:10::101
IPv6_address 2001:db8:16:10::102
}
}
}
Again, the above is taken from fw1; on fw2, the UDP section has the source/destination IP addresses inverted.
The "Address Ignore" block should list ALL the IPs the firewall has (or can have) on local interfaces, including the VIPs. It doesn't hurt to include some extra IP (eg those of the other firewall).
The "well-formed ruleset"
(Just in case you're testing with everything set to ACCEPT and it doesn't work)
One thing that is mentioned in the documentation but imho not stressed enough is the fact that the firewall MUST have what they call a "well-formed ruleset", which essentially means that the firewall must DROP (not accept nor reject) any packet it doesn't know about. It's explained better in this email from the netfilter mailing list.
We briefly touched the issue earlier; even with conntrackd, it may still happen that during a failover the firewall that is becoming active receives some packet related to a session it doesn't yet know about (eg. because failover isn't instantaneous and the firewall hasn't finished committing the external cache); under normal conditions, the firewall's local TCP/IP stack may try to process such packets, resulting in potential disruption since it would almost certainly end up sending TCP RST or ICMP errors to one or both connection parties. One case is especially critical, it goes like this: an internal client is receiving data (eg downloading) from an external server, a failover happens, some of the packets the server is sending hit the firewall that is becoming active, which isn't fully synced yet, so it sends RST to the server. Result: the server closes its side, but the client in the LAN still thinks the connection is valid, and hangs waiting for data. If it's the client that gets the RST, what happens depends on the specific application; it may exit, or retry.
The moral of the story thus is that, for the failover to be seamless, it's critical that the firewall ignore (drop, not reject) packets it doesn't know about. In particular, a packet coming from the outside belonging to a NATed connection looks just like a packet addressed to the firewall, if the firewall has no state for the connection; so those packets have to be DROPped in the INPUT chain. In practice, this probably means a default DROP policy for the INPUT chain (ok, being a firewall it probably does it anyway, but better be explicit). Similarly, a DROP policy for the FORWARD chains will also help.
All this works because if the firewall drops unknown traffic, TCP or whatever protocol the communicating parties are using will notice the loss and sort it out (eg by retrasmitting packets).
Testing
So for example we can download some Debian DVD on two or more clients, to keep them busy with a long-running TCP connection:
wget -O/dev/null 'http://cdimage.debian.org/debian-cd/6.0.7/amd64/iso-dvd/debian-6.0.7-amd64-DVD-1.iso'
Open some other less intensive task, like ssh or telnet sessions, and perhaps watch some Internet video. In short, create many connections to the Internet through the active firewall. Once all this is in place, log into the active firewall (the one that has the VIPs), and stop or restart keepalived, to force a failover to the other firewall (if you stop keepalived, remember to start it again later before doing further tests). If everything is set up correctly, the VIPs should move to the other box and the active sessions in the LAN should keep working flawlessly. That's it! For more thorough testing, the failover process can be repeated many times (within reason), and every time it should be transparent to clients.
Here's a script that forces a failover between fw1 and fw2 and viceversa every N seconds, where N is a random number between 61 and 120 (of course, this is just for testing purposes):
#!/bin/bash
declare -a fws
fws=( 172.16.10.101 172.16.10.102 )
i=0
maxi=$(( ${#fws[@]} - 1 ))
while true; do
[ $i -gt $maxi ] && i=0
fw=${fws[$i]}
#echo "deactivating $fw"
ssh root@"${fw}" '/etc/init.d/keepalived restart'
# interval between 61 and 120 seconds
period=$(($RANDOM % 60 + 61))
#echo "sleeping $period seconds..."
sleep $period
((i++))
done
